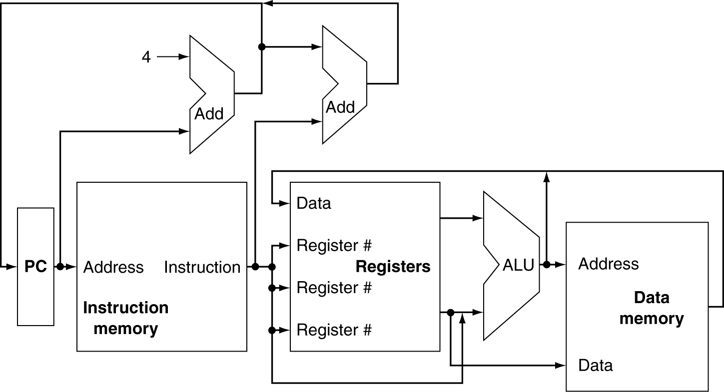
Life of a triangle - NVIDIA's logical pipeline
Fermi是第一个实现了一个完全可扩展图形引擎的英伟达GPU,并且它的核心架构同样可以在Kepler和Maxwell上看到。这篇文章聚焦在图形的视角来看GPU是怎么工作的。
Pipeline Architecture Image

GPUs are super parallel work distributors
为什么这么复杂?在图形中,每个draw调用都可能产生不同数量的三角形。Clipping之后顶点的个数也是不同于开始的数量。经过背面和深度剔除,不是所有的三角形都需要显示在屏幕上。一个三角形的屏幕尺寸可能意味着它需要上百万个像素或者一个也不需要。因此,现代GPU让它的图元(三角形,线,点)遵从一个逻辑管线,而不是一个物理管线。在G80统一架构之前,管线是不同的阶段,并且渲染工作将在这些stages上逐个运行。G80复用一些单元做顶点和片元着色器计算,但它仍然有一个串行的处理过程,比如图元装配,光栅化等等。直到Fermi,管线变为全并行,意味着芯片利用多个引擎实现了一个逻辑管线。
以2个三角形A和B为例,它们的部分工作可能在不同的逻辑管线阶段。A已经被转换并且将被光栅化。它的一些像素可能已经正在运行像素着色器,一部分像素可能被深度测试剔除了,一部分像素可能已经被写到framebuffer,并且还有一部分可能正在等待。并且紧接着我们可以fetch三角形B的顶点。所以每个三角形必须经历各个逻辑步骤。让draw调用的三角形显示在屏幕上的工作被分割为多个小任务,甚至能够并行的子任务。每个任务被调度到可用的资源上,这些资源不限制任务的类型(顶点着色可以并行于像素着色)。
考虑一条扇出的河流。并行管线流,每个流是相互独立,并且每个流有他自己的时间线,其中一些可能还有分支。
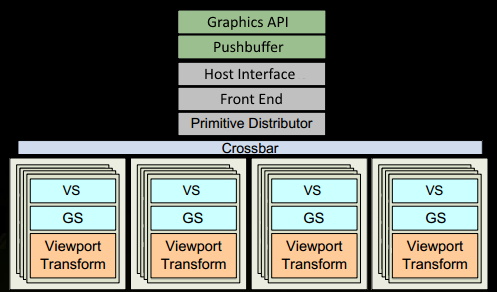
GPU architecture
Fermi 有一个类似原理的架构。有一个Giga Thread Engine用于管理所有进行中的工作。GPU被分为多个GPC(Graphics Processing Cluster), 每一个多个SMs(Streaming Multiprocessor)和一个Raster Engine. 在这种工艺下有许多interconnect, 最值得注意的是一个Crossbar,它允许跨GPC或其他功能单元,如ROP(Render Output Unit)子系统进行工作迁移。程序员关心的shader程序的执行是在SM上完成的。它包含多个Cores,这些Core完成线程的数学操作。一个线程可能是一个顶点或像素着色器调用。这些Cores和其他单元由Warp Scheduler来驱动,其管理一个有32个线程组成的名叫warp的group并且传递指令到Dispatch Units去执行。
GPU上真正有多少个这些单元依赖于芯片配置。SM自身的设计(比如core的数量,指令单元,调度器等)也在随着一代一代不断的变化以帮助芯片高效的扩展适配从高端的桌面机到手机。

The logical pipeline
我们假设drawcall引用一些索引和vertexbuffer,已经填充了数据并且存在于GPU的DRAM中,并且只用于vertex-和pixelshader(GL: fragmentshader)。
- 程序通过图形API触发一个drawcall。到达驱动后再某些点上做一些合法性检查,如果是合法的则以GPU可识别的编码形式插入命令到pushbuffer内。许多瓶颈发生在CPU侧,这也是为什么程序员用好API很重要
- 经过一会儿或者一个显示的flush调用,驱动已经buffer了足够的工作在pushbuffer中,并且发送到GPU去处理。GPU侧的主机接口挑选出能够被前端处理的命令
- 我们开始Primitive Distributor中的工作分配,通过处理indexbuffer中的索引并且生成发送给多个GPC的三角形batch
- 在一个GPC内,SM的Poly Morph Engine负责根据三角形顶点索引拉取顶点数据(Vertex Fetch)
- 拿到顶点数据后,32个线程的warp被在SM内调度并且工作在这些顶点上
- SM的warp scheduler按顺序发射整个warp的指令。线程以lock-step的形式运行每条指令并且如果它们不应该被真正执行的时候能够被单独masked out。可能有多个原因需要masking,比如当前指令是if(true)分支并且线程具体数据评估为false,或者一个loop结束退出的时候,一个线程达到退出条件,另一个还没有。所以shader中有过多branch divergence的情况下,将增加一个warp中所有线程的耗时。线程不能单独提前,only as a warp!但是warp之间是独立的
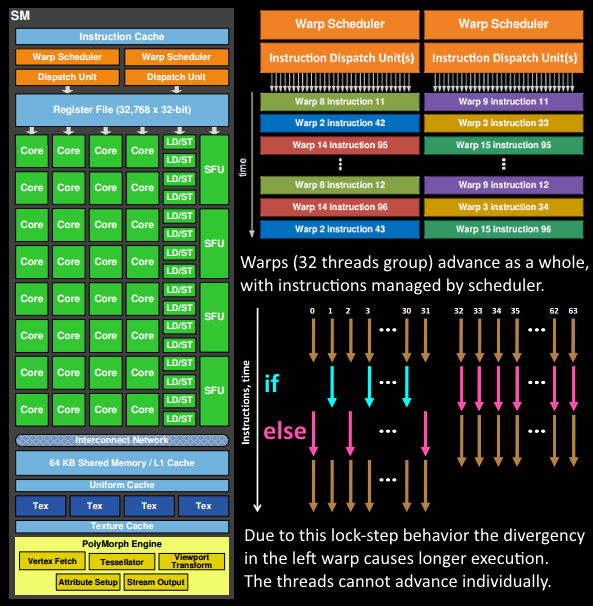
- warp的指令可能被一次就完成或者花费多轮dispatch。例如SM相比基础数学操作有较少的load/store单元
- 一些指令相比其他指令可能花费更长的时间,尤其memory load操作的时候,warp scheduler可能会简单的切到另一个不等待memory操作的warp。这是一个关键的概念,GPU怎么克服memory多些的latency,它只是简单的通过切出一组激活的线程。 为了快速切换,由scheduler管理的所有线程在寄存器文件中有它们自己的寄存器。一个shader需要的寄存器越多,支持的线程或warp就越少。能够切换的warp越少,等待指令完成时能够用于切换的warp就越少。
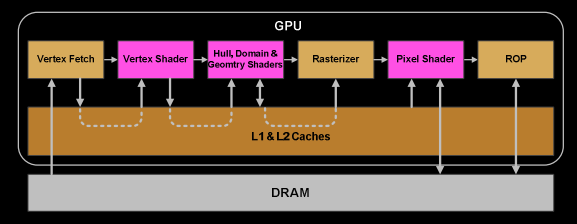
- 一旦warp完成了所有vertex-shader的指令,它的结果将被Viewport Transform处理。三角形将被clipspace volume进行裁剪,并且做好了光栅化前的准备。我们用L1和L2 Cache做这种夸任务的数据交换
- 现在到了有意思的地方,我们的三角形即将被分割并将离开当前生存的GPC。三角形的bounding box用于决定那个raster engines需要去工作,每个引擎覆盖多个屏幕上的tiles。它通过Work Distribution Crossbar发送三角形到一个或多个GPC。现在有效的将三角形拆分为了多个小任务。
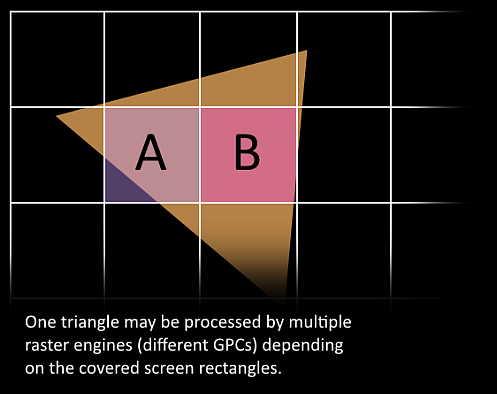
- Attribue Setup确保顶点着色器产生的输出是对像素着色器友好的格式
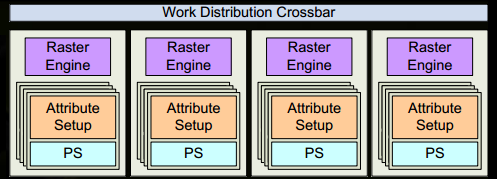
- GPC的Raster Engine工作在它接收的三角形上,并且生成像素信息
- 再一次我们将32个像素线程作为一个batch,或者更好的说法是8个2x2的pixel quads,这是工作在pixel shader上的最小单位。这个2x2的quad允许我们去计算纹理mip map filtering的导数
- 在vertex-shader阶段的warp scheduler同样现在作用于pixel-shader线程。在这里锁步处理会非常方便,因为我们能几乎能自由的访问一个pixel quad里的所有值,同时所有的线程也能保证它们的数据在相同的指令点上计算(NV_shader_thread_group)

- 到这里,我们的像素着色器已经完成了颜色的计算,并且也已经有了depth的值。在这里,我处理hand over数据给某一个ROP之前,我们不得不携带三角形的原始API顺序。在这一步,深度测试,blending等基于frambuffer执行,这些操作需要原子操作以确保一个三角形的颜色和另一个三角形的深度不会同时出现在一个同一个像素上
Ohoo! 咱们已经完成了,我们已经写了一些像素到渲染目标。希望这些信息能够帮助理解一些GPU内的work/data flow。可能也能帮助我们理解GPU的另一面为什么同步是如此负面的影响。一方面不得等待直到所有的事情都被完成并且没有新的任务被提交,也就意味着发送新work的时候,需要等待一会直到所有的阶段都重新有了load,尤其在打的GPU中。简单说,有些阶段可以并行处理,有些地方必须按顺序处理,这就要求必须以更高协作能力来达到更高的效率。
Reference
https://developer.nvidia.com/content/life-triangle-nvidias-logical-pipeline