Understanding Nvidia Tensor Core
对HPC和AI前所未有的加速
Tensor Core能够进行mixed-precision计算,能在保证准确度的情况动态调整计算精度增加吞吐量。
- Revoluinary AI Training
- Breakthrough AI Inference
- Advanced HPC
Understanding Tensor Core
What are CUDA cores?
.png)
What are Tensor Cores?
Tensor Core是一个能够进行混合精度训练的特殊核。这个特殊核的第一代通过一个融合的乘加计算,允许两个4x4 FP16矩阵相乘并加到一个4x4的FP16或者FP32矩阵。之所以称为mixed precision computation是因为输入的矩阵可能是低精度的FP16,而最终输出是FP32(只有很少的精度损失)
How do Tensor Cores work?
The basic role of a tensor core is to perform the following operation on 4x4 matrices:
D = A×B + C
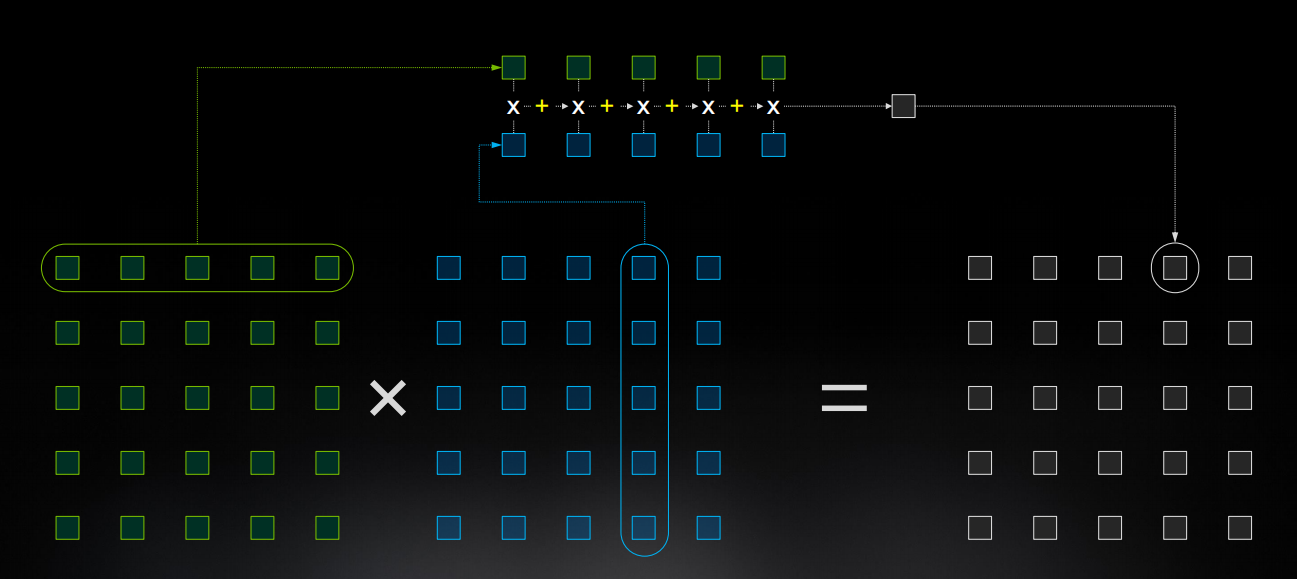
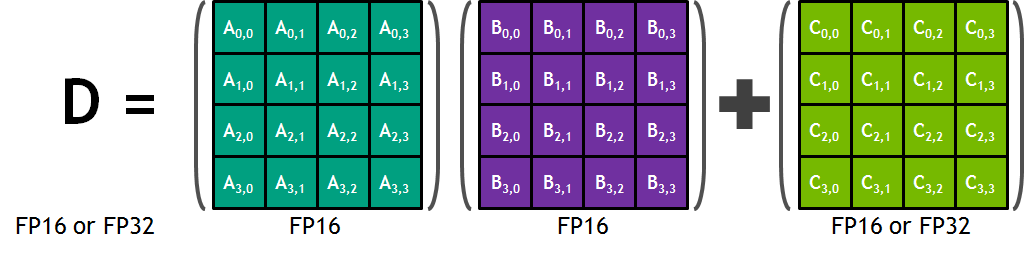
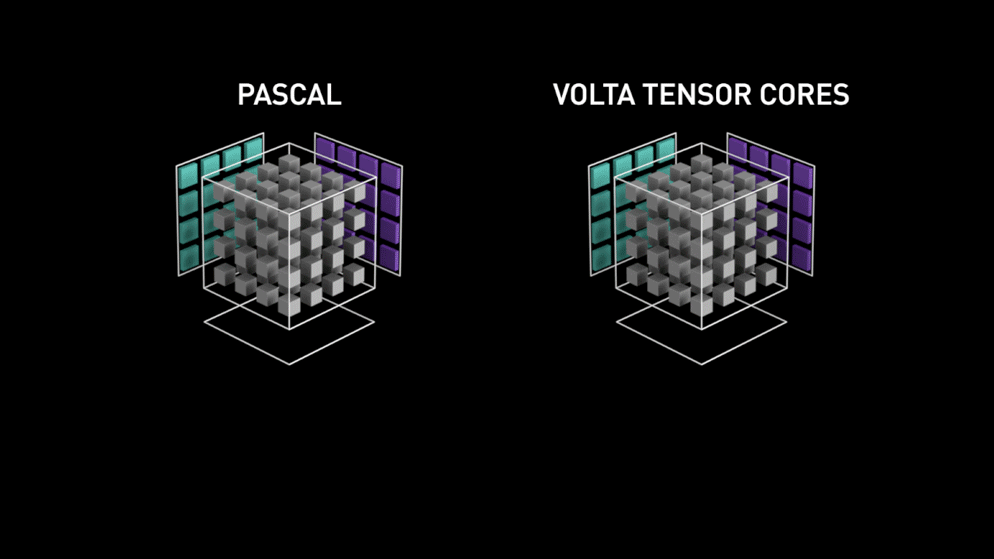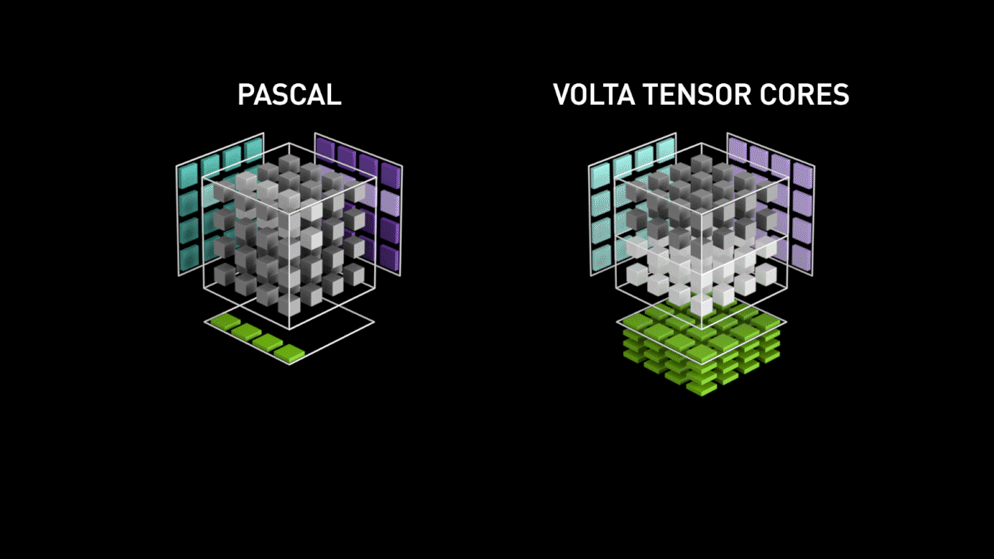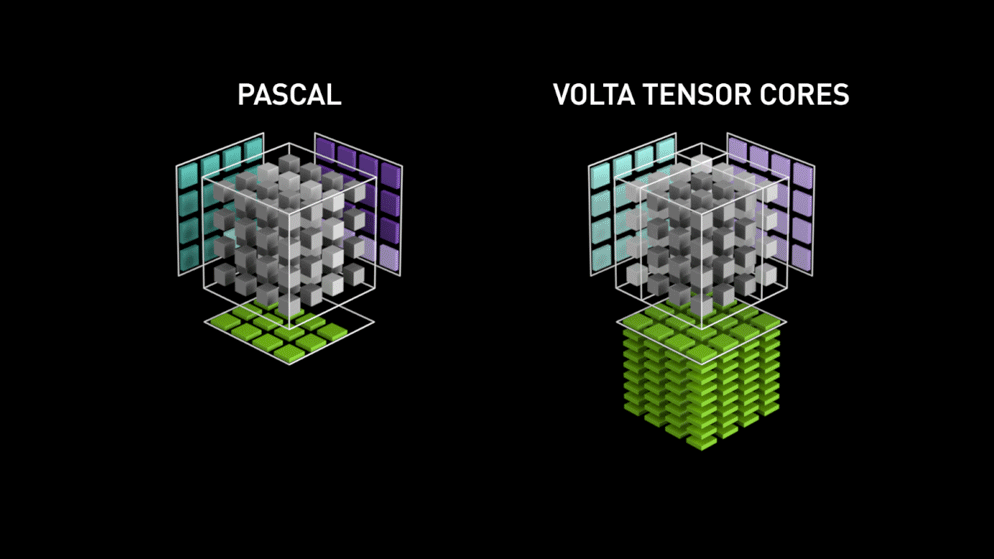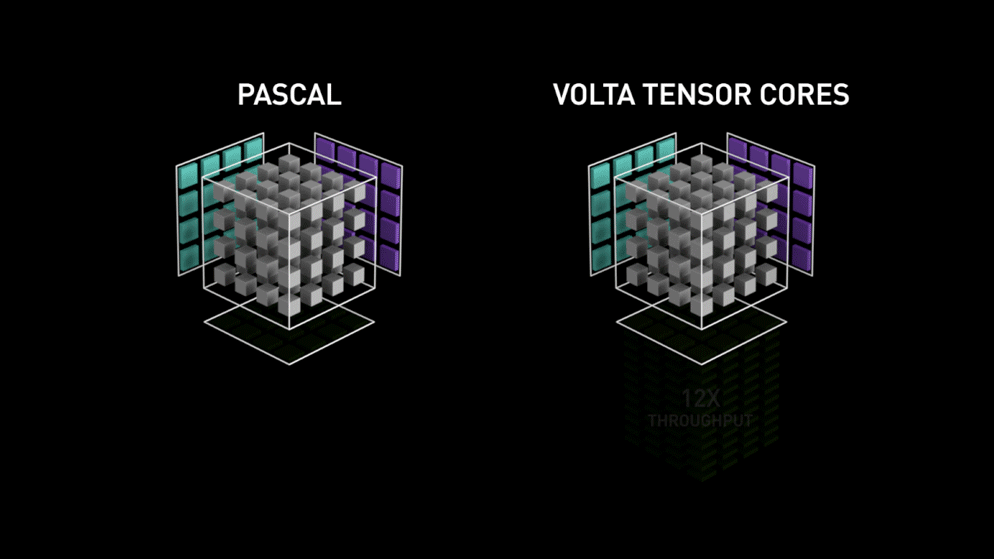
两个矩阵A和B相乘,如下图所示,两个矩阵在中间立方体的外侧(注意,在左侧的矩阵A是转置矩阵)。立方体自身代表生成完整4x4输出矩阵的64个元素。想象一下,立方体内所有64个blocks一旦被点亮,水平层根据输入瞬间一起完成乘法,接下来,垂直线瞬间求和,一个完整的生成矩阵就掉下来了,然后与下面白色线框内的矩阵C(转置矩阵)求和,变成下一个输出矩阵D,并被push进结果栈。
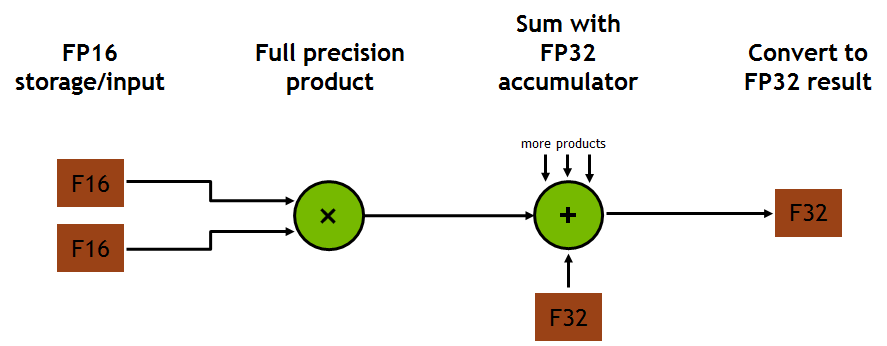
张量核心如何工作的实现无疑比图解所显示的要复杂得多。它可能涉及一个多层次的FMA管道,一层一层向下发展。然后设想连续的C矩阵从顶部下降,累积每层乘积的部分和。
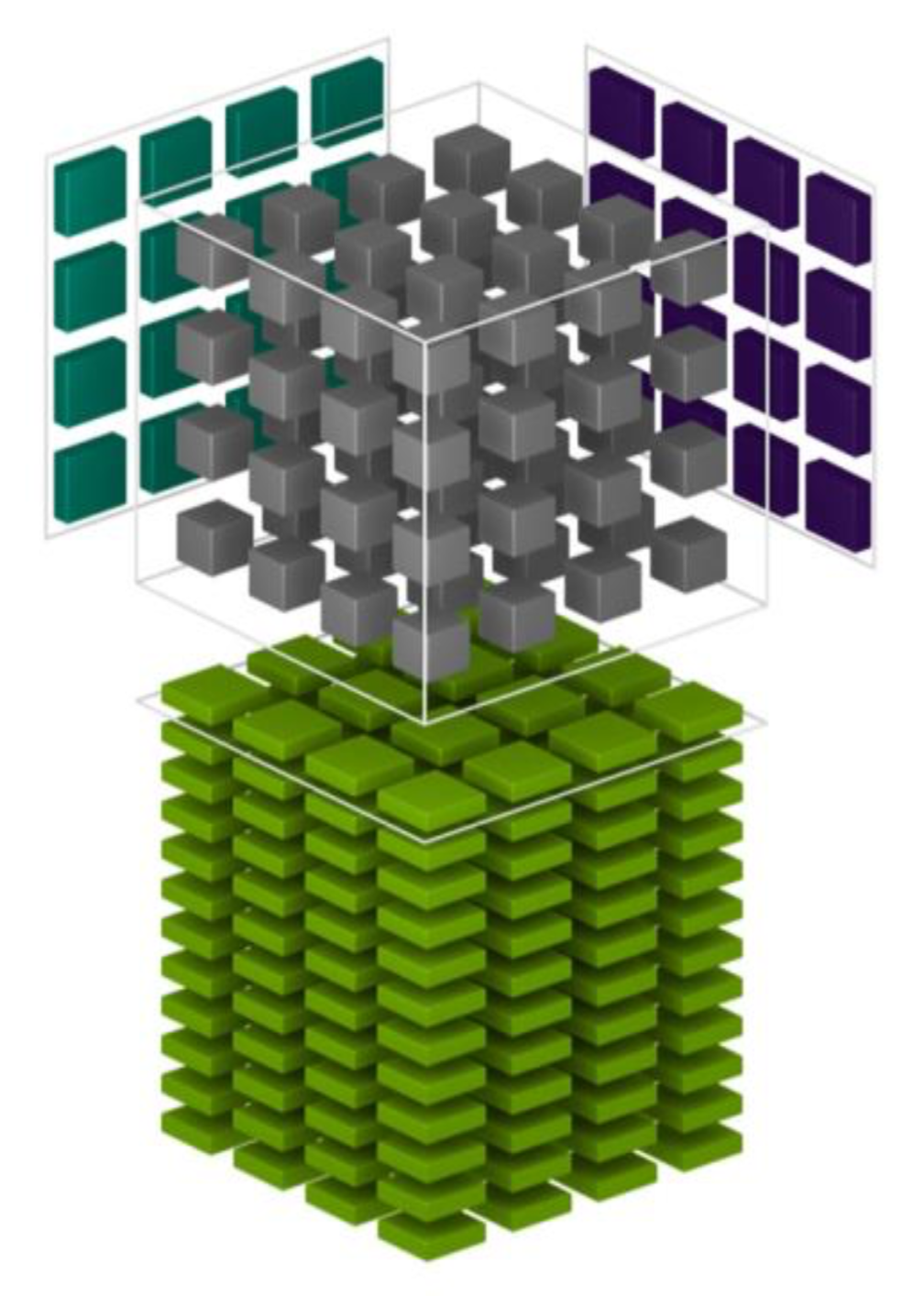
NVIDIA Volta Tensor Cores (1th)
第一代Tensor Core是来自于Volta GPU微架构。 Designed specifically for deep learning, the first-generation Tensor Cores in NVIDIA Volta™ deliver groundbreaking performance with mixed-precision matrix multiply in FP16 and FP32, up to 12X higher peak teraFLOPS (TFLOPS) for training and 6X higher peak TFLOPS for inference over NVIDIA Pascal.
The Tesla V100 GPU contains 640 Tensor Cores: eight (8) per SM and two (2) per each processing block (partition) within an SM. In Volta GV100, each Tensor Core performs 64 floating point FMA operations per clock, and eight Tensor Cores in an SM perform a total of 512 FMA operations (or 1024 individual floating point operations) per clock. Tesla V100’s Tensor Cores deliver up to 125 Tensor TFLOPS for training and inference applications.
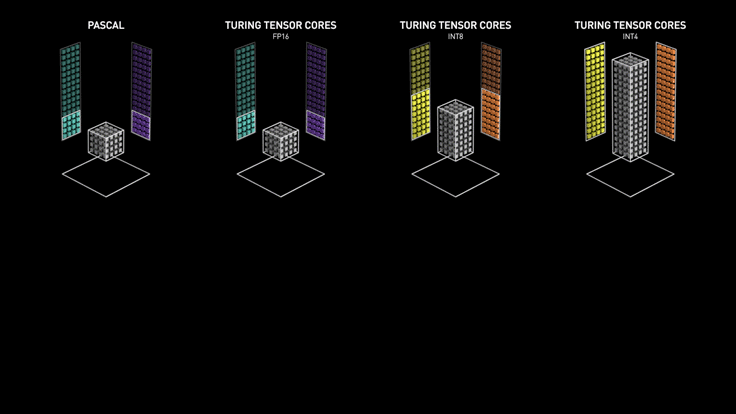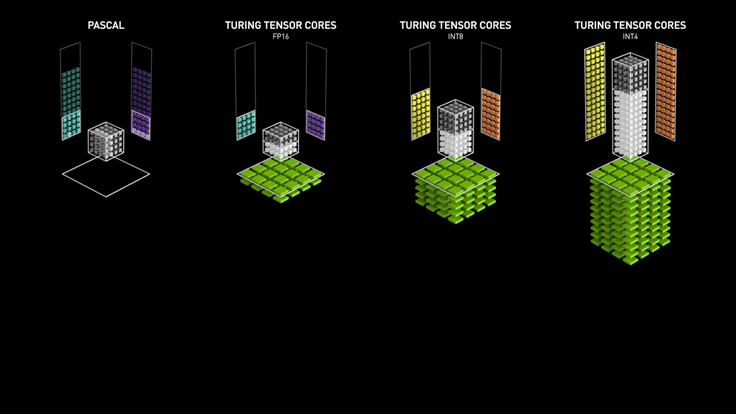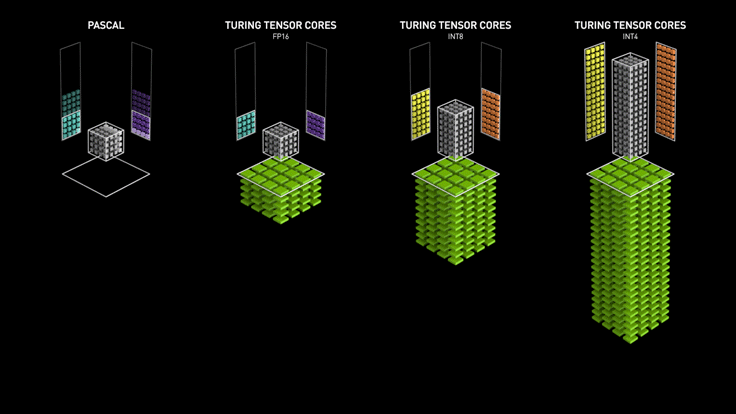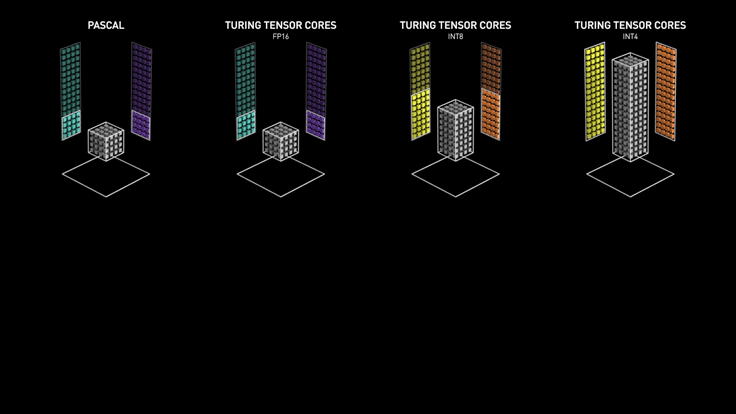
NVIDIA Turing Tensor Cores (2th)
NVIDIA Turing™ Tensor Core technology features multi-precision computing for efficient AI inference. Turing Tensor Cores provide a range of precisions for deep learning training and inference, from FP32 to FP16 to INT8, as well as INT4, to provide giant leaps in performance over NVIDIA Pascal™ GPUs
除此之外,Turing架构也引入了Ray Tracing Cores用于计算图形的可视化的属性,比如3D环境中的光和声音。
NVIDIA Ampere Architecture Tensor Cores (3th)
Ampere架构Tensor Core的构建是基于前一代的创新,仅引入了新精度的数据类型TF32和FP64来加速和简化AI的使用,并将Tensor Core的功能扩展到了HPC。
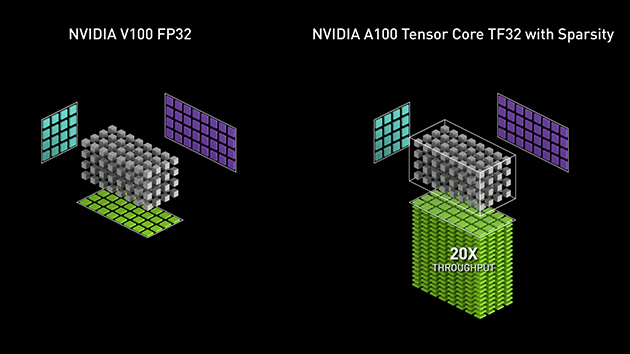
NVIDIA H100 Tensor Cores (4th)
自从Tensor Core技术的引入,Nvidia GPU的峰值性能已经增加了60倍。Hopper架构的第四代Tensor Core通过引入Transfor Engine用一个新的8-bit floating point精度(FP8)达到了6倍于FP16的性能提升(for trillion-parameter model training).
- FP8
Tranformer AI网络由于大和数学计算,其训练时间可能被拉长到数月。Hopper的新FP8的性能可以达到6倍于Ampere的FP16。FP8被用在Tranformer Engine中,Hopper的Tensor Core实际就是被设计用于加速Tranformer模型的加速。

- FP16
Hopper Tensor Core boost FP16 for deep learning.

- TF32
Delivering AI speedup
- FP64
Accelerating a whole range of HPC application that need double-precision math

- INT8
第一次被引入是在Turing架构中,INT8 Tensor Core大大加速了推理的吞吐量

The Most Powerful End-to-End AI and HPC Data Center Platform
| Hopper | Ampere | Turing | Volta | |
|---|---|---|---|---|
| Supported Tensor Core precisions | FP64, TF32, bfloat16, FP16, FP8, INT8 | FP64, TF32, bfloat16, FP16, INT8, INT4, INT1 | FP16, INT8, INT4, INT1 | FP16 |
| Supported CUDA® Core precisions | FP64, FP32, FP16, bfloat16, INT8 | FP64, FP32, FP16, bfloat16, INT8 | FP64, FP32, FP16, INT8 | FP64, FP32, FP16, INT8 |