An Introduction to Modern GPU Architecture
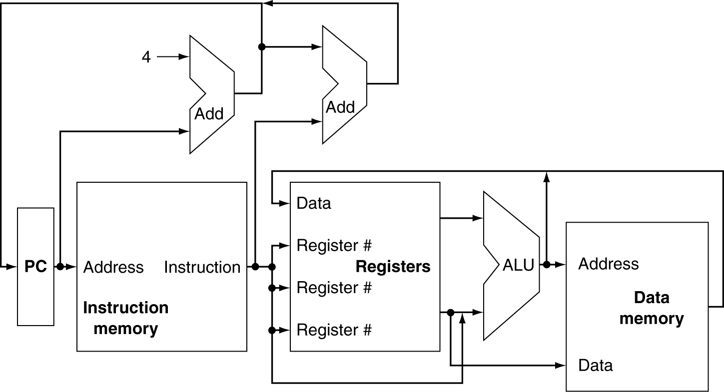
1. Graphics Pipelines For Last 20 Years
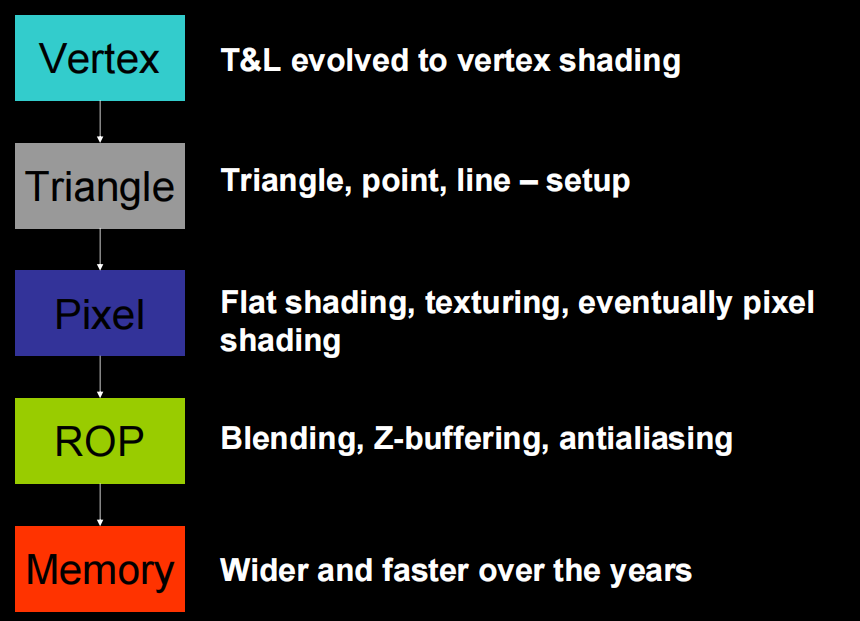
2. Unified Pipeline
Why Unify
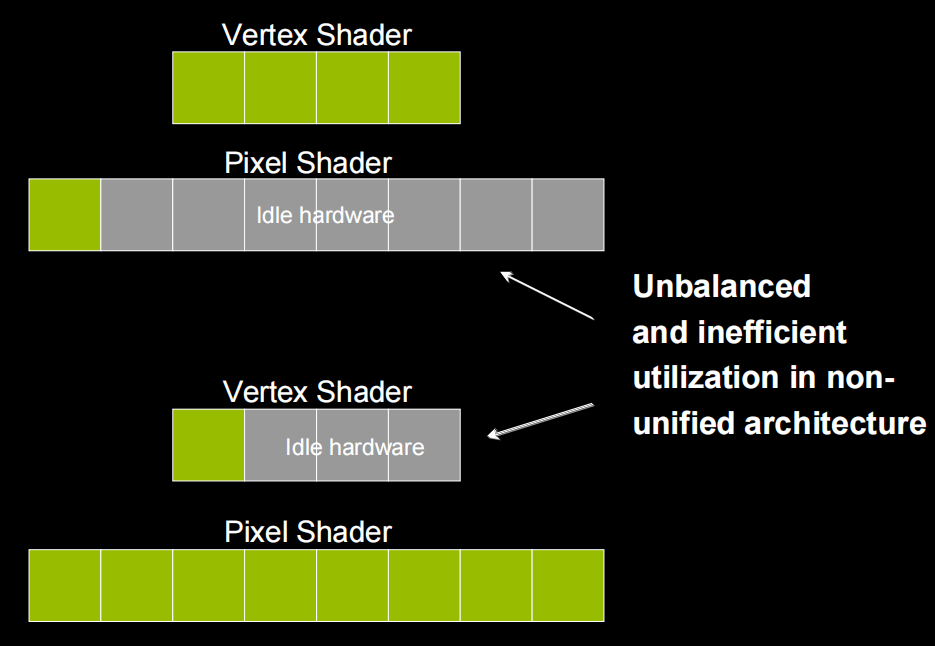
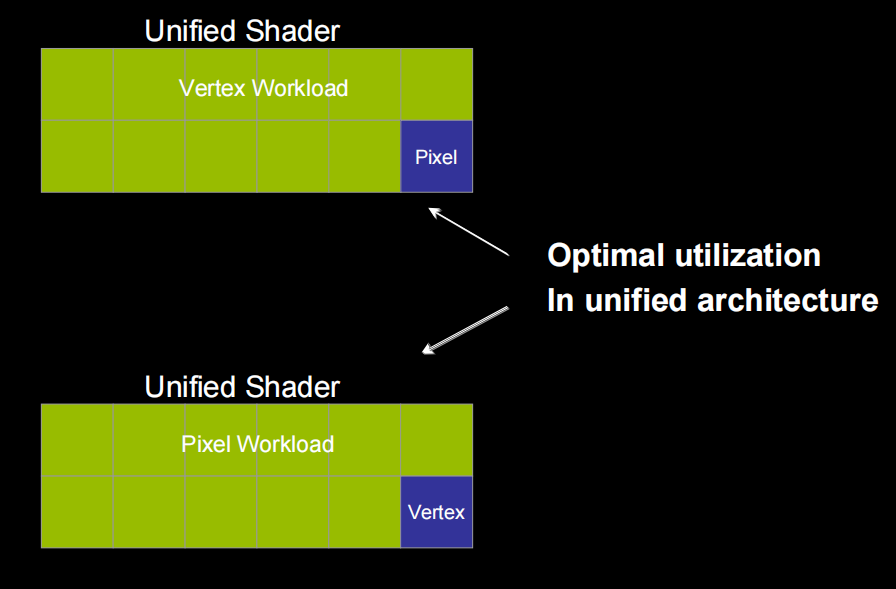
Why Scalar Instruction Shader
- Vector ALU
efficiency varies
 co-issue – better but not perfect
co-issue – better but not perfect

Vector/VLIW architecture require more compiler work, scalar always 100% efficient, simple to compile, build a unified architecture with scalar cores where all shader operations are done on the same processors.
3. Stream Processing
How CPUs and GPUs differ
- Latency Intolerance vs Latency Tolerance
- Task Parallelism vs Data Parallelism
- Multi-thread Cores vs SIMT Cores
- 10s of Threads vs 10000s of Threads
CPUs is low latency low throughput processors GPUs is high latency high throughput processors
GPUs can have more ALUs for the same sized chip and therefore run many more threads of computation, modern GPUs run 10,000s of threads concurrently
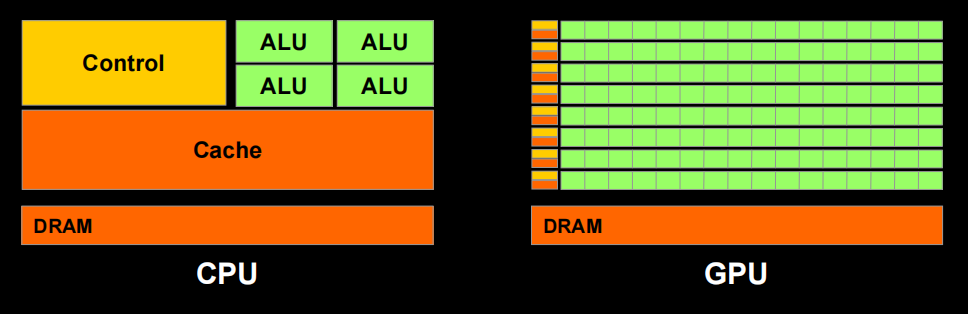
What is the Stream Processing
Given a (typically large) set of data(“Stream”), run the same series of operations (“Kernel” or “Shader”) on all of the data(SIMD)
- GPU designed to solve problems that tolerate high latencies
- High latency tolerance, lower cache requirements
- Less transistor area for cache, more area for computing units
- More computing units, 10,000s of SIMD threads and high throughput
- Threads managed by hardware, you are not required to write code for each thread and manage them yourself
- Easier to increase parallelism by adding more processors
So, fundamental unit of a modern GPU is a stream processor.
4. G80 and GT200 Streaming Processor Architecture
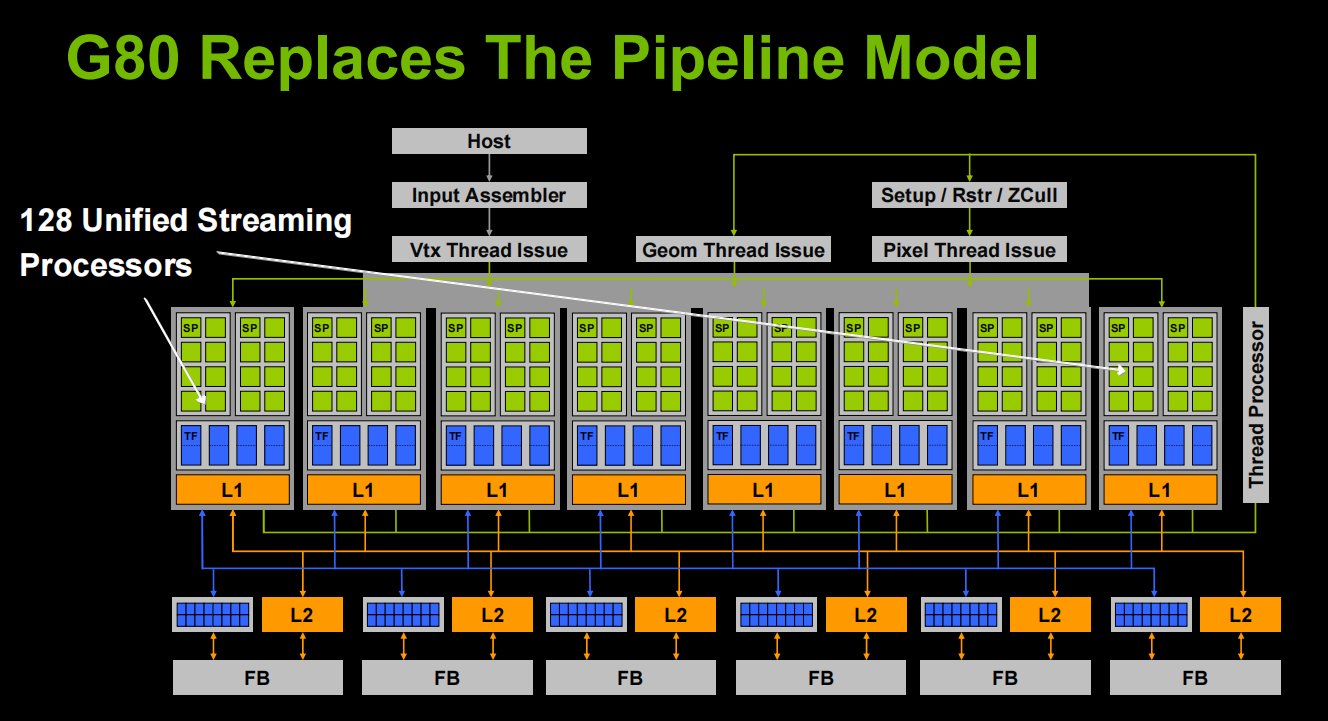
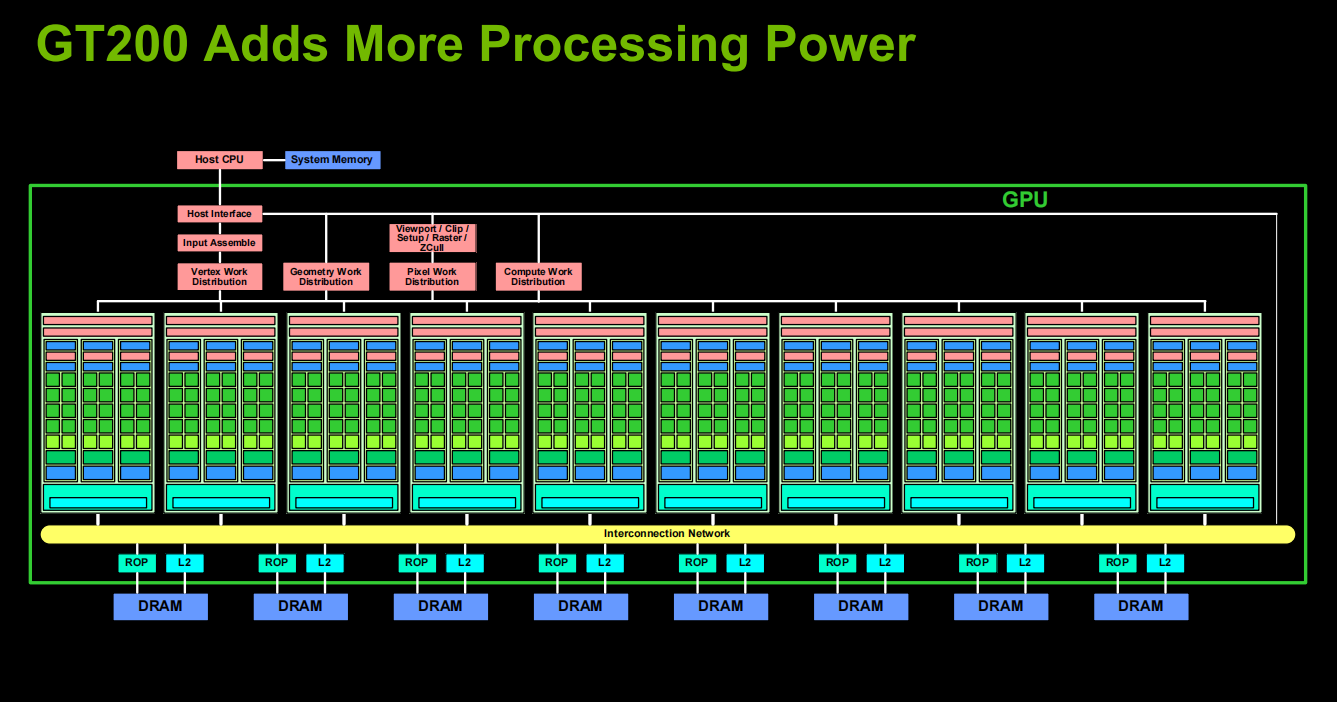
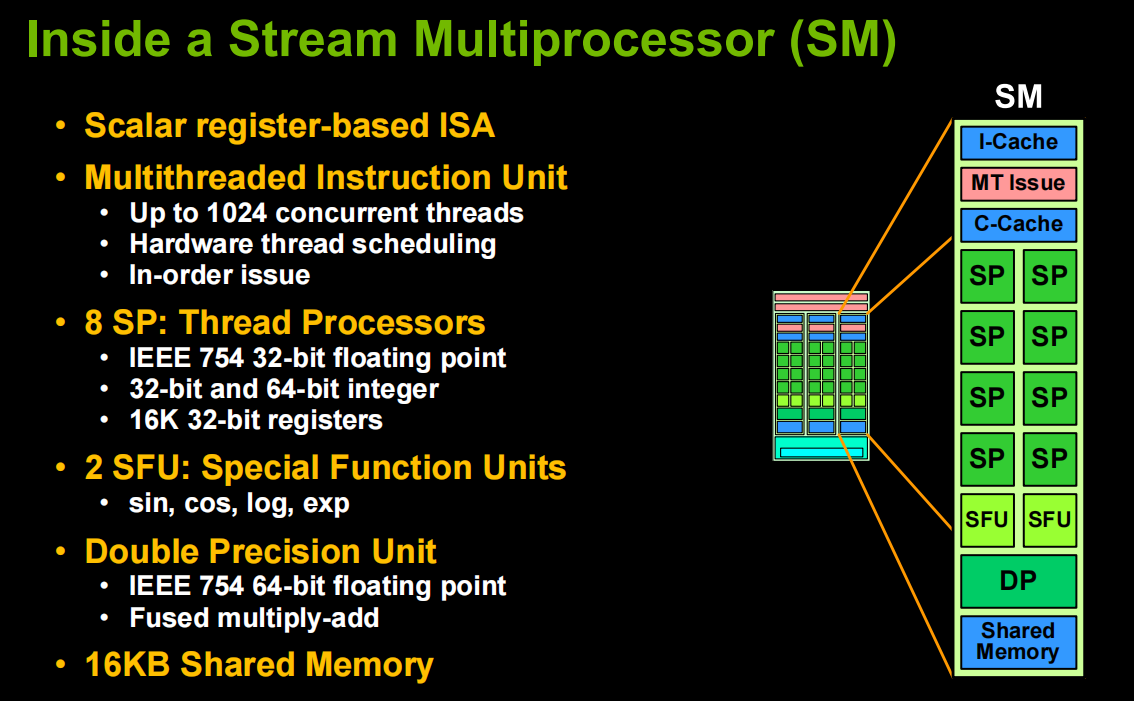
- Workloads are partitioned into blocks of threads among multiprocessors
- a block runs to completion
- a block doesn’t run until resources are available
- Allocation of hardware resource
- shared memory is paritioned among blocks
- registers are partitioned among threads
- Hardware thread scheduling
- any thread not waiting for something can run
- context switching is free -every cycle
Need large number of threads to hide latency
- Minimum: 128 threads/SM typically
- Maximum: 1024 threads/SM on GT200
Warp size
If threads diverge, both sides of branch will execute on all 32. More efficient compared to architecture with branch efficiency of 48 threads
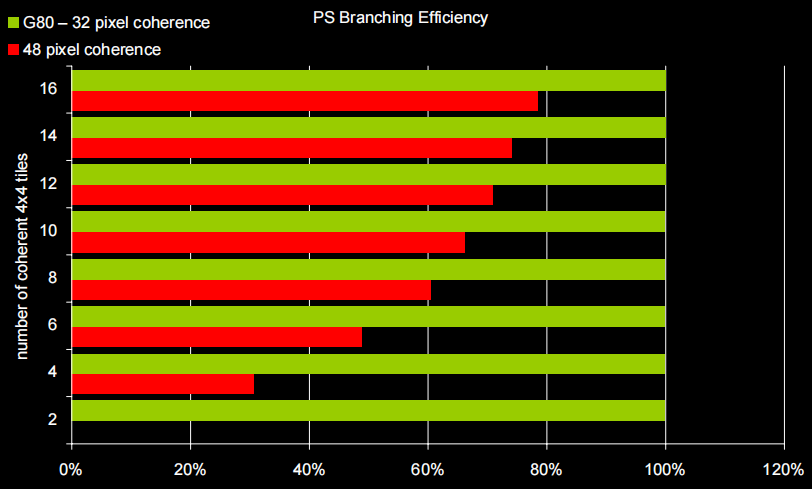
5. Conclusion: G80 and GT200 Streaming Processor Architecture
- Thread scheduling is automatically handled by hardware
- Memory latency is covered by large number of in-flight threads
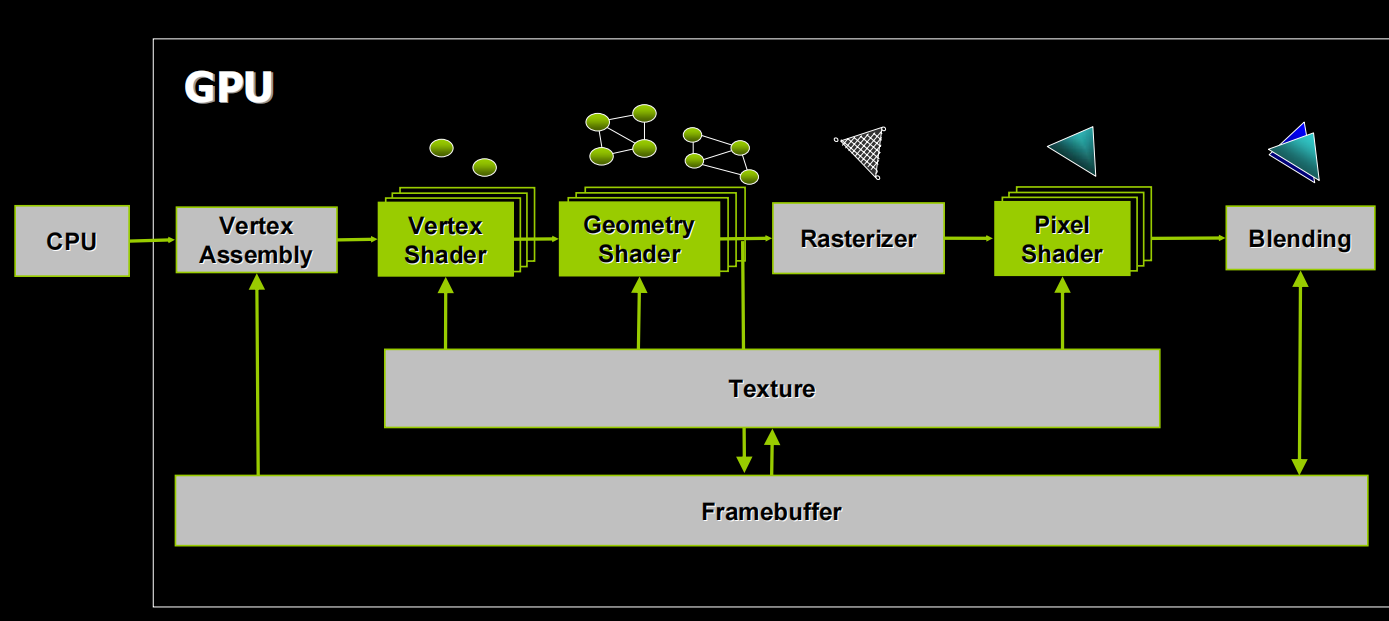
6. Stream Processing for Graphics
Graphics Pipeline(Logical View)
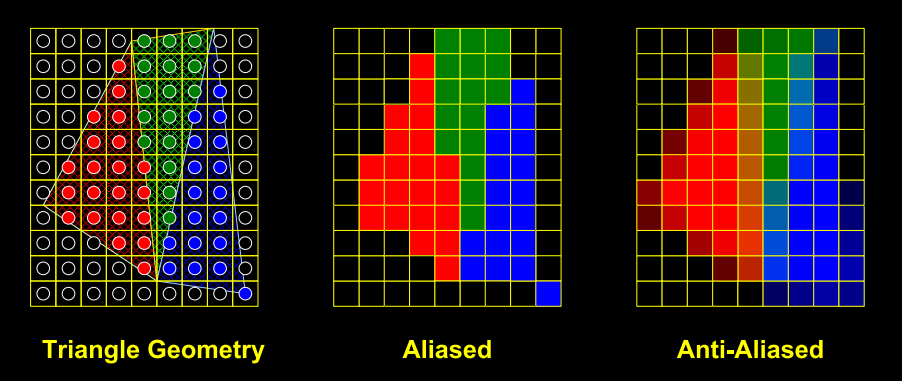
Anti-Aliasing
7. CUDA
A scalable parallel programming model and software environment for parallel computing
Reference
https://download.nvidia.com/developer/cuda/seminar/TDCI_Arch.pdf